The primary purpose of this assignment is to get familiar with the characteristics of MapReduce jobs and learn the resource optimization methods for running MapReduce jobs in Amazon EC2 cloud.
With the deployment of web applications, scientific computing, and sensor networks, large datasets are collected from users, simulations, and the environment. As a flexible and scalable parallel programming and processing model, recently MapReduce has been widely used for processing and analyzing such large scale datasets. However, data analysts in most companies, research institutes, and government agencies have no luxury to access large private Hadoop clouds. Therefore, running Hadoop/MapReduce on top of a public cloud has become a realistic option for most users.
Running a Hadoop cluster on top of a public cloud shows very different features compared to on a private Hadoop cluster. First, for each job a dedicated Hadoop cluster will be started on a number of virtual nodes. There is no multi-user or multi-job resource competition happening within such a single-job Hadoop cluster. Second, it is now the user's responsibility to set the appropriate number of virtual nodes for the Hadoop cluster. This number may differ from application to application and depend on the amount of input data.
The problem of optimal resource provisioning involves two intertwined factors: the cost of provisioning the virtual nodes and the time finishing the job. Intuitively, with a larger amount of resources, the job can take shorter time to finish. However, resources are provisioned at cost. It is tricky to find the best setting that minimizes the cost. With other constraints such as a time deadline or a financial budget to finish the job, this problem appears more complicated. Amazon has developed the Elastic MapReduce that runs on-demand Hadoop/MapReduce clusters on top of Amazon EC2 nodes. However, it does not provide tools to address these decision problems.
We can analyze the MapReduce workflow and derive a flexible modeling method (check the CRESP method for details). Students should have understood the workflow well with the lecture slides. Let M be the number of data blocks, m be the number of Map slots in the whole system, R be the user-specified number of Reduce tasks, and r be the number of Reduce slots. Let Tm, Tr, and To be the approximate cost of a Map task, a Reduce task, and task management cost, respectively. According to the MapReduce workflow shown in Figure 1, we can model the cost function as (M/m)Tm+(R/r)Tr+To. Typically, we often set the number of Reduce tasks R appropriately to r, i.e., R=r. With the parameters M,m,R,r, and the processing logic, we can finally derive a cost function T(M,m,R) = b0+b1(M/m) + b2(M/R) + b3(M/R)log(M/R)+ b4M +b5R +e, where b0 to b5 are to be set for a specific job, and e is the stochastic error for modeling the uncertainty. This cost function is good for any job with Reduce tasks in linear or O(N log (N)) complexity to the Reduce's input data N.
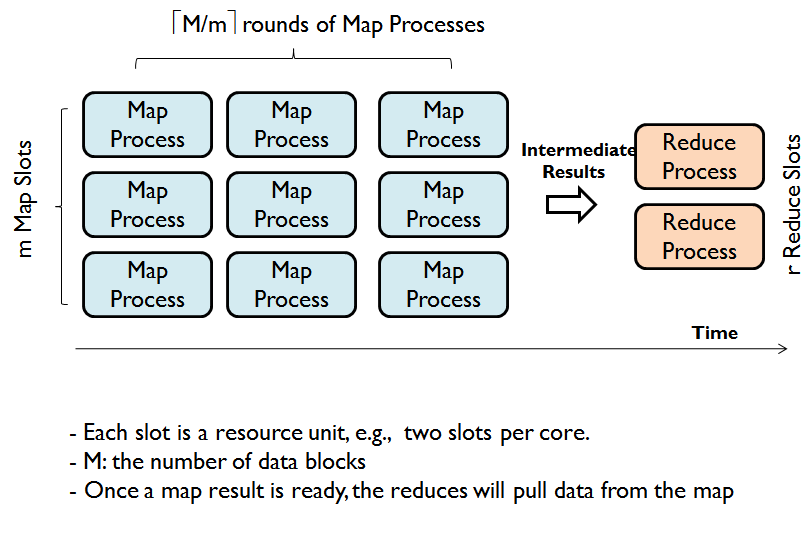
Now our task is to determine the parameters b0 to b5. We use linear regression to find these parameter settings. The first step will be collecting the training data, i.e., the time cost for a specific MapReduce program with different combinations of M,m, and R. This training data is obtained by test-running relatively small input data (i.e., small M settings) on small scale clusters (i.e., small m and R settings) to find the corresponding time costs. The result will be 4-tuples (M, m, R, T).
Ideally, you will need to setup EC2 clusters of variant numbers of medium or large-size nodes in range [3, 20] for test runs, where the maximum number 20 is allowed by Amazon for normal users. For simplicity, you can setup a cluster of fixed size, e.g., 10 nodes, while use Hadoop's fair scheduler to adjust the available Map and Reduce slots (i.e., m and R). You will also use Hadoop version 1.2.1 in the experiments. Students should have done the Hadoop on AWS lab prior to this lab. Otherwise, they should check that lab to learn the basic steps setting up a Hadoop cluster with EC2 nodes.
We will work on two testing MapReduce programs to derive their cost models. The WordCount program and the Sort program are in Hadoop's official example packages. You can run the following commands to get them executed with R reducers.
hadoop jar $HADOOP_HOME/hadoop-examples-1.2.1.jar wordcount <input> <output> -Dmapreduce.job.reduces=R hadoop jar $HADOOP_HOME/hadoop-examples-1.2.1.jar sort <input> <output> -Dmapreduce.job.reduces=R
Note that the parameters b0 to b5 are all non-negative to make the model practical for actual costs. You can use either the non-negative linear regression function lsqnonneg in Matlab or lassocv (the cross-validation version of lasso regression) in Python Scikit Learn. Cross-validation or the leave-one-out (LOO) evaluation methods (for small training data) should be used to drive the model quality. We will discuss more details about regression modeling in the lectures.
Once you have understood all the preparation materials, answer the following questions:
Question 1.1 When the number of input data blocks are larger than the number of available Map slots, how does the Hadoop system schedule the Map tasks?
Question 1.2 Why do we normally set the number of Reduce tasks to approximately the number of Reduce slots? In what situations, it makes sense to set the number of Reduce tasks larger than the number of Reduce slots?
Question 1.3 How to evaluate the quality of linear regression models? Read the literature or lecture slides and answer it concisely.
Question 1.4 Design 20 test runs appropriately and execute them with the EC2 cluster. Write down the 4-tuples (M, m, R, T) in the report, and describe the experiment method you use. Use cross-validation or leave-one-out to train and evaluate the models, and describe the evaluation method and the result in the report.
Question 2.1 Your level of interest in this lab exercise (high, average, low);
Question 2.2 How challenging is this lab exercise? (high, average, low);
Question 2.3 How valuable is this lab as a part of the course (high, average, low);
Question 2.4 Are the supporting materials and lectures helpful for you to finish the project? (very helpful, somewhat helpful, not helpful);
Question 2.5 How much time in total did you spend in completing the lab exercise;
Turn in the report that answers all the questions to the Pilot project submission before the deadline. Also print out a hardcopy and turn in to the class.
Make sure that you have terminated all instances after finishing your work! This can be easily done with the AWS web console.
| This page, first created: June 2015; last updated: June 2015 |