CloudVista: interactive visual analysis of large data in the cloud
Data Intensive Analysis and
Computing (DIAC) Lab, the Ohio Center of Excellence on Knowledge Enabled
Computing (Kno.e.sis Center)
Wright State University
Motivation:
With the
deployment of more and more cloud applications, large datasets are now
generated, stored and analyzed in the cloud. A critical problem is how to
efficiently analyze such large datasets using the parallel processing power
provided by the cloud. A few relational data analysis techniques, data mining
algorithms, and machine learning algorithms have been developed for handling
the data in the cloud. However, visual exploratory data analysis, such as
visual cluster analysis, which is very important for human involved knowledge
discovery, presents unique challenges for the data hosted in the cloud. We list
some of the challenges:
First, new
cloud-based processing framework and algorithms are needed for efficiently
generating visualization from the large datasets. In particular, visualization
models and data transformation algorithms that encode non-scalable components
need to be redesigned to fit the scalable processing framework.
Second,
processing large data inevitably brings significant delays, which conflicts
with the unique requirement of interactivity in visual analysis. How to
elegantly handle the delays and guarantee sufficient interactivity is the key
to interactive visual data exploration.
Third, economics of processing is a unique feature of cloud applications. We should understand the time-resource complexity of each component and design a workflow to minimize both the financial cost and the latency.
The CloudVista approach:
We design the CloudVista approach for interactively visualizing data clusters in the large datasets hosted in the cloud. CloudVista utilizes our previously developed VISTA visualization model and develops a set of methods to address the interactivity problem. We represent one static visualization as a visual frame. A series of interactive operations will generate a number of continuously changing visual frames, which help the user understand the clustering structure in a dynamic way. The technical problems include (1) how to generate a visual frame and a number of visual frames in a parallel program? (2) how to handle the delays between interactive operations?
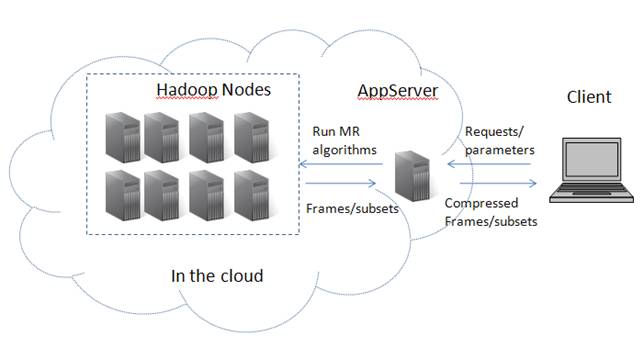
The first problem can be easily addressed by using the VISTA visualization model. We address the second problem with two approaches. First, we change the traditional visual interactive model to a hybrid batch-interactive model. Second, we use the randomized continuous frame generation algorithm to generate a series of continuously changing visual frames.
Batch-interactive
model: In the
traditional interactive model, the system waits for the user’s interactive
operation. The interactive operation just changes the visualization parameters.
With the new visualization parameters, the system updates the visualization.
This
real-time feedback model is not realistic for data in the cloud because of the
long delay caused by cloud-side processing. It is also difficult to predict the
user’s operation based on historical operations. Therefore, we propose a
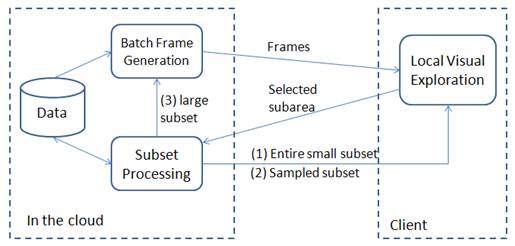
batch-interactive model as the following figure shows.
The main idea is to generate a batch of related visual frames in the server for each round of exploration, while the user can explore the series of visual frames locally until a request for a new batch is issued. To implement the batch generation algorithm, the key is to automatically generate a series of correlated visual frames, which is addressed by the RandGen algorithm.
RandGen
frame generation algorithm: the RandGen frame generation algorithm is used to automatically
generate a series of correlated visual frames. The design of this algorithm is
based on the special properties of the VISTA visualization model.
The VISTA
visualization model is used to visualize the clustering structure of a
multidimensional dataset. It maps the data from the high-dimensional space to
the two dimensional visual space, partially preserving the relative Euclidean
distance relationship. As a result, the clustering structure (based on
Euclidean distance) is partially preserved – the well-separated clusters in the
original space may be visualized as overlapped clusters. The VISTA
visualization is determined by dimensional parameters. Continuously changing
these parameters will create an “animation” of the visualized clustering
structure.
Compared to
the normally used dimensional interactive tuning, RandGen generates the
dimensional parameter settings for many frames in a batch. It starts with the
user’s initial dimensional setting and then randomly changes the dimensional
setting by –s or +s with 50% to 50% probability without user’s intervention.
We have
shown that the visualized distances follow certain pattern in the randomized
process – overall, the close points will move closely on average, while distant
points will be visually separated in high probability.
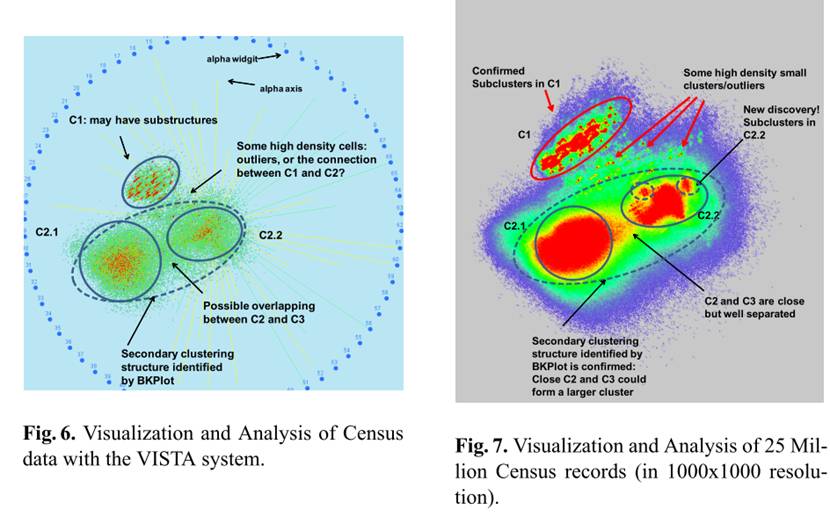
The following figure shows a comparison between visualizing a sample set (one thousand records, 68 dimensions) with the VISTA system and visualizing the extended large set (25 million records, 68 dimensions). We can see that, by exploring the entire dataset, more details of the clustering structure can be observed (the right subfigure). The visual frame is encoded with the density information and visualized with the heatmap technique. The more dense the cells have records mapped on, the warmer color the cells are visualized – clusters are located at the dense areas.
Related Resources:
1. A demo system will be available soon, check this page for details.
2. The original VISTA interactive visual cluster exploration system.
3. Some video clips: exploring extended Census data (25 million records, 68 dimensions, 5.3GB data) and extended KDDCUP99 data (40 million records, 41 dimensions, 13.5GB data)
4. Keke Chen, Huiqi Xu, Fengguang Tian, Shumin Guo: “CloudVista: visual cluster exploration for extreme scale data in the cloud”, Scientific and Statistical Database Management Conference, Portland OR, 2011